In the vast universe of life sciences, enzymes are the "molecular engines" that drive everything. The discovery of new enzymes is far more than adding a new functional annotation to the database. It is profoundly affecting the boundaries of our understanding of the basics of life, driving the industrial transformation of biotechnology, and carrying the hope of mankind to cope with global challenges.
From the "miracle of survival" in extreme environments, to the "core engine" of industrial green manufacturing, to the "precision tool" of gene editing, the birth of each new enzyme may open a new era of applications. Today, we will delve into the strategic value of new enzyme discovery and systematically analyze the five core strategies that are reshaping the future of biocatalysis driven by AI and big data.
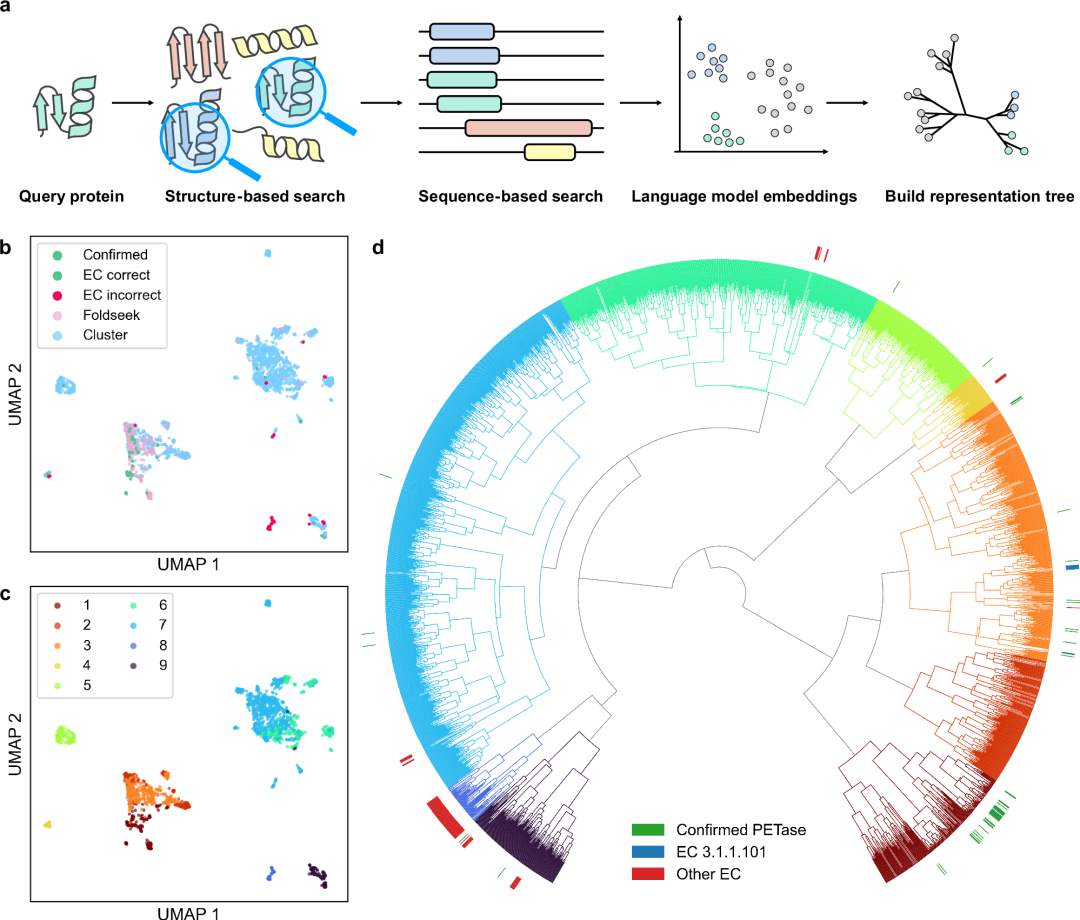 Figure 1. Discovery process of new PETase enzyme based on structural similarity
Figure 1. Discovery process of new PETase enzyme based on structural similarity
 Figure 2. Schematic diagram of enzyme digestion substrate. The pocket similarity hypothesis is a strong hypothesis for new enzyme discovery.
Figure 2. Schematic diagram of enzyme digestion substrate. The pocket similarity hypothesis is a strong hypothesis for new enzyme discovery.
Five core strategies: from “random screening” to “precise mining”
Traditional enzyme discovery relies on "random screening", which is inefficient. Today, "precision mining" based on big data, AI and evolutionary theory has become mainstream. Here’s an in-depth look at the five core strategies:1. Sequence-based discovery of new enzymes
Principle hypothesis : "Homology determines function." Key catalytic sequences are highly conserved during evolution, and new enzymes are located by comparing similarities. Implementation method :use BLAST Perform a global comparison, or use HMMER Construct a Hidden Markov Model (HMM) to mine conserved motifs for specific enzyme families. real case : Zhang Feng team (Broad Institute) discovered a variety of new CRISPR-Cas systems (such as Cas12) through sequence comparison and HMM mining of massive bacterial genomes, which greatly enriched the gene editing toolbox. paper :Discovery and functional characterization of diverse Cas9 effector proteins (DOI: 10.1126/science.aad5227)2. Methods based on structural similarity and clustering
Principle hypothesis : "Structure is more conserved than sequence". Even if the sequence similarity is less than 20%, the three-dimensional fold may be stable, allowing the discovery of "distant homologous enzymes". Implementation method :use AlphaFold2 or ESMFold Predict large-scale protein structures and then pass Foldseek or Dali Perform high-throughput alignment and clustering. real case : Martin Steinegger Team (Seoul National University) Clustered hundreds of millions of predicted protein structures to identify thousands of novel enzyme families in "structural space" that could not be discovered by traditional sequence comparisons. Paper: Clusteringpredicted structures at the scale of the known protein universe (DOI: 10.1038/s41586-023-06510-w)
Figure 1. Discovery process of new PETase enzyme based on structural similarity
3. Based on pocket similarity algorithm
Principle hypothesis : "The local active center determines the nature of catalysis." Ignore the overall folding and focus only on the geometry, electrostatic potential, and hydrophobicity of the active pocket. Implementation method :use P2Rank or DeepPocket Identify binding sites and use PocketAlign and other algorithms to compare the physical and chemical characteristics of the pockets. real case : Come to Luhua Team (Peking University) Through active pocket similarity search, new metabolic enzymes that can convert cholesterol in the complex human intestinal flora were accurately identified. paper :Computational discovery of cholesterol-lowering bacteria from the humangutmicrobiota (DOI: 10.1016/j.chom.2022.09.007)
Figure 2. Schematic diagram of enzyme digestion substrate. The pocket similarity hypothesis is a strong hypothesis for new enzyme discovery.