在生命科学的浩瀚宇宙中,酶是驱动万物运转的“分子引擎”。新酶的发现,远不止是在数据库中新增一条功能注释,它正深刻影响着我们对生命基础认知的边界,驱动着生物技术的产业变革,更承载着人类应对全球性挑战的希望。
从极端环境下的“生存奇迹”,到工业绿色制造的“核心引擎”,再到基因编辑的“精准工具”,每一款新酶的诞生,都可能开启一个全新的应用时代。今天,我们将深入探讨新酶发现的战略价值,并系统解析在AI与大数据驱动下,那些正在重塑生物催化未来的五大核心策略。
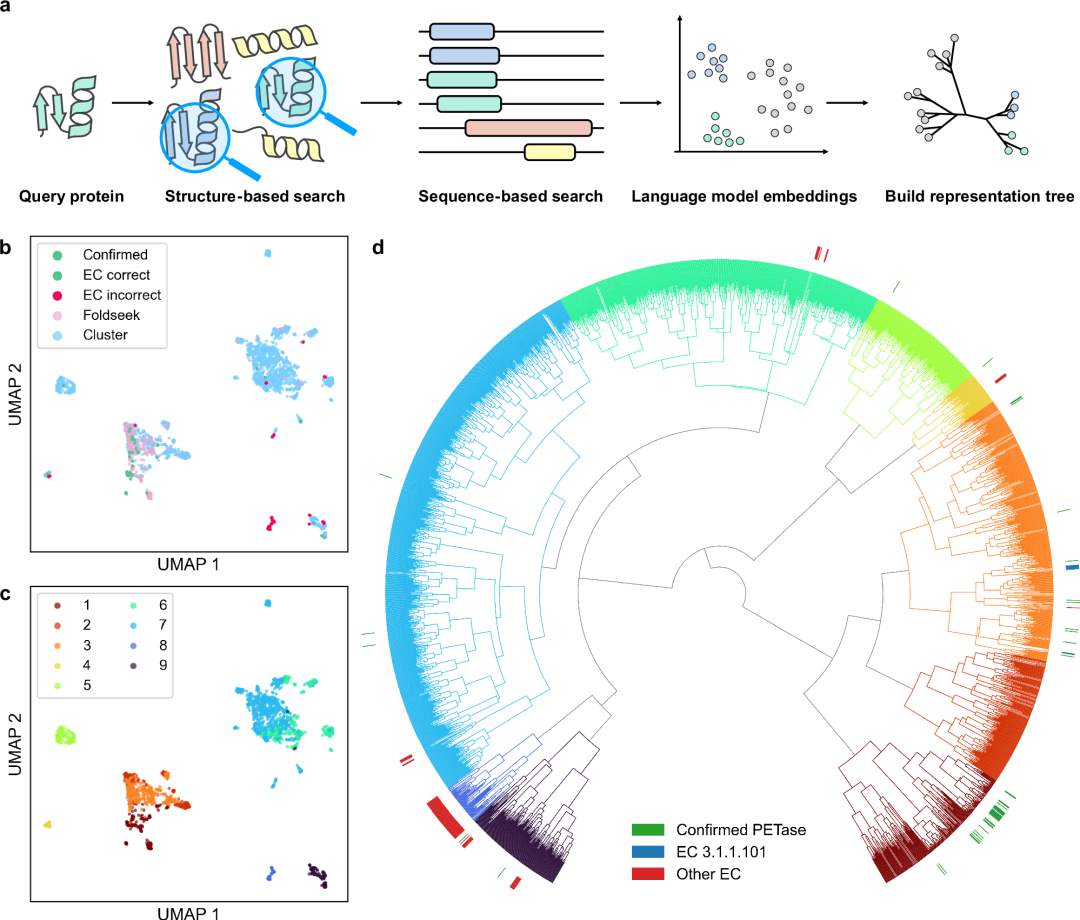 图1. 基于结构相似性的PETase新酶发现流程
图1. 基于结构相似性的PETase新酶发现流程
 图2. 酶切底物示意图。口袋相似性假设是新酶发现的一种强假设。
图2. 酶切底物示意图。口袋相似性假设是新酶发现的一种强假设。
五大核心策略:从“随机筛选”到“精准挖掘”
传统的酶发现依赖“随机筛选”,效率低下。如今,基于大数据、AI及进化理论的“精准挖掘”已成为主流。以下是五种核心策略的深度解析:1. 基于序列的新酶发现
原理假设 :“同源性决定功能”。进化中关键的催化序列高度保守,通过比对相似性定位新酶。 实现方式 :利用 BLAST 进行全局比对,或使用 HMMER 构建隐马尔可夫模型(HMM),挖掘特定酶家族的保守基序。 真实案例 : 张锋团队 (Broad Institute)通过对海量细菌基因组的序列比对和HMM挖掘,发现了多种新型CRISPR-Cas系统(如Cas12),极大地丰富了基因编辑工具箱。 论文 :Discovery and functional characterization of diverse Cas9 effector proteins (DOI: 10.1126/science.aad5227)2. 基于结构相似性及聚类的方法
原理假设 :“结构比序列更保守”。即使序列相似度低于20%,三维折叠也可能稳定,从而发现“远源同源酶”。 实现方式 :利用 AlphaFold2 或 ESMFold 预测大规模蛋白结构,再通过 Foldseek 或 Dali 进行高通量比对与聚类。 真实案例 : Martin Steinegger 团队 (首尔大学)对数亿个预测蛋白结构进行聚类,从“结构空间”中识别出数千个传统序列比对无法发现的新型酶家族。 论文:Clusteringpredicted structures at the scale of the known protein universe (DOI: 10.1038/s41586-023-06510-w)
图1. 基于结构相似性的PETase新酶发现流程
3. 基于口袋相似性算法
原理假设 :“局部活性中心决定催化本质”。忽略整体折叠,仅关注活性口袋的几何形状、静电势和疏水性。 实现方式 :使用 P2Rank 或 DeepPocket 识别结合位点,利用 PocketAlign 等算法对比口袋的理化特征。 真实案例 : 来鲁华团队 (北京大学)通过活性口袋相似性搜索,在复杂的人类肠道菌群中,精准锁定了能转化胆固醇的新型代谢酶。 论文 :Computational discovery of cholesterol-lowering bacteria from the humangutmicrobiota (DOI: 10.1016/j.chom.2022.09.007)
图2. 酶切底物示意图。口袋相似性假设是新酶发现的一种强假设。