High-throughput enzyme screening: How to find your “selected enzyme” from hundreds of millions of candidates?
Today, with the explosion of synthetic biology and biocatalysis industries, enzymes serve as the "core chip of biocatalysis". Their catalytic efficiency, substrate specificity, stability and other properties directly determine the cost limit and industrial feasibility of biomanufacturing processes.
Traditional shake flask or single-tube screening methods can only produce dozens to hundreds of clones per day, which has long become a bottleneck in enzyme engineering applications. Faced with the genotypic diversity of tens of thousands, millions or even hundreds of millions in natural metagenomic libraries, directed evolution libraries or AI design libraries, traditional methods are obviously inadequate.
The emergence of high-throughput enzyme screening technology has increased the throughput of enzyme activity screening by tens of thousands of times, significantly compressing the enzyme directed evolution cycle that originally took several years to within months or even weeks, becoming a key tool to break through this bottleneck.
Today, we will talk in depth about the core logic and practical process of high-throughput enzyme screening.
1. Core principles of high-throughput enzyme screening
The essence of high-throughput enzyme screening is to accurately convert the catalytic activity (phenotype) of the enzyme into a physical signal that can be quickly detected, quantified, and sorted by high-throughput equipment, while ensuring the absolute one-to-one correspondence between the encoding gene (genotype) of the enzyme and the corresponding phenotype, and ultimately quickly enriching enzyme molecules that meet the target performance from a massive enzyme library. Its core principle can be broken down into two parts:
-
Detectable and high signal-to-noise ratio conversion of enzyme activity signals
The catalytic reaction of the enzyme itself cannot be directly read by the device. It must go through a stable system to convert the catalytic process of "converting substrate into product" into a quantifiable optical signal (mainstream is absorbance, fluorescence, chemiluminescence), which is the prerequisite for screening.
According to the conversion method of the substrate, detection systems can be divided into two categories: direct detection systems and indirect coupling detection systems.
Direct detection system: The principle of this type of method is to use the substrate or product itself to carry a detectable label (such as an optical group), and the catalytic reaction can directly cause signal changes. For example, through fluorescence resonance energy transfer (FRET) substrates, chromophore-modified substrates, etc., changes in fluorescence intensity or absorbance before and after the reaction can directly reflect the amount of product generated, which is positively correlated with enzyme activity. Its advantages are simple operation, low background interference, easy automation, and is especially suitable for ultra-high-throughput screening.
Indirect coupling detection system: Through 1-2 steps of coupling enzyme reaction, the product of the target catalytic reaction is converted into a detectable optical signal. The most common one is the dehydrogenase coupling system, which indirectly quantifies the progress of the target reaction by detecting the absorbance of coenzyme NAD (P) H at 340 nm or the fluorescence at 460 nm. The advantage is its wide adaptability, and most enzymatic reactions can achieve signal conversion through coupling.
-
Ultra-high-throughput monoclonal isolation and signal sorting
The throughput bottleneck of traditional screening lies in the large reaction volume and the inability to achieve parallel isolation of single clones. The core breakthrough of high-throughput screening is to achieve absolute physical isolation of single clones through micro-volume reaction units. Each reaction unit only contains one genotype of enzyme and its catalytic reaction system to avoid signal cross-contamination while achieving millions of parallel reactions.
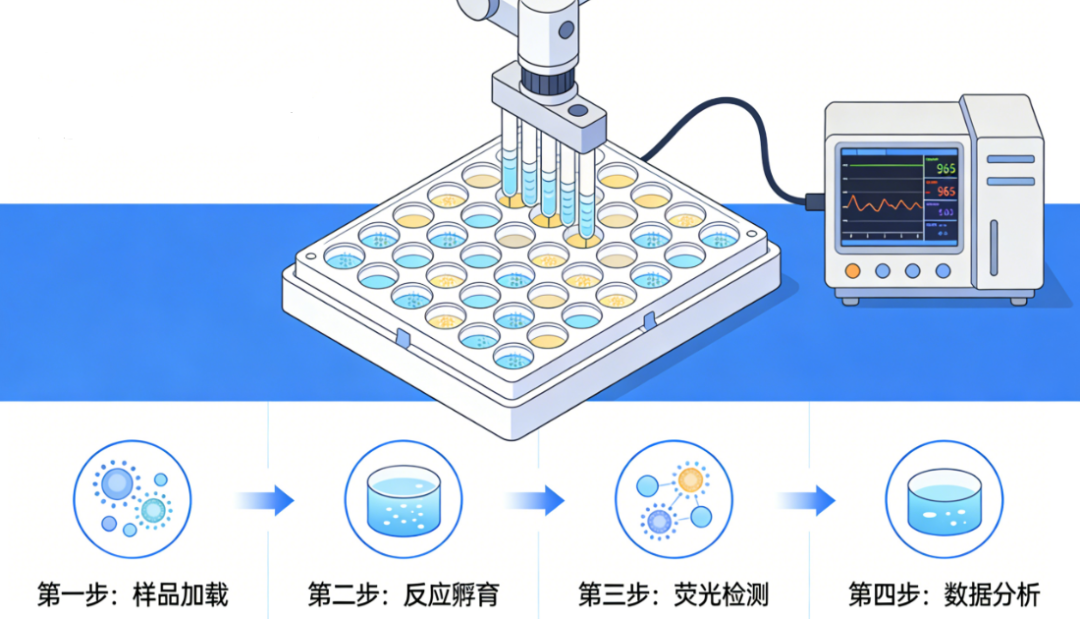
Figure 1 Core steps of high-throughput enzyme screening
2. The underlying logic of high-throughput enzyme screening
Many practitioners fail in enzyme screening, and the root cause often lies not in operational techniques, but in the failure to clarify the fundamental logic behind screening. High-throughput enzyme screening is not a "one-time detection experiment", but a complete closed loop of work from target definition to verification iteration. Its underlying logic can be broken down into four core links, which are interlocking and indispensable.
-
Logical starting point: accurately define screening goals
The real starting point for screening is not to construct a library, but to clarify "what kind of enzymes are to be screened out." Fuzzy application requirements must be transformed into specific indicators that can be measured in experiments and can exert selection pressure, mainly including:
(1) Core catalytic functions: target substrate, target product, reaction type.
(2) Core performance indicators: such as activity threshold, substrate specificity, tolerance to temperature/acid-base/organic solvents, catalytic conversion rate, etc.
(3)真实筛选压力:筛选体系应尽可能模拟实际工业应用环境(如高温、高底物浓度、存在有机溶剂等),否则筛出的酶很可能无法落地。
-
Logical core: ensuring reliable correlation between genotype and phenotype
This is the soul of the entire screening system and the source of most failure cases. The so-called "genotype-phenotype correlation" means that the detected "high activity signal" (phenotype) must correspond one-to-one with the gene (genotype) encoding the enzyme and be strictly bound to avoid signal confusion or loss of genetic information. Once the association fails, even if a strong positive signal is detected, it cannot be traced back to the corresponding gene, and the screening will fail. Different screening platforms (such as microplates, droplets, surface displays) have different correlation mechanisms and need to be designed accordingly.
-
Logical key: efficient and specific enrichment of positive clones
The core goal of high-throughput screening is not to "find the perfect enzyme in one experiment", but to efficiently and specifically enrich potential positive clones from massive libraries, greatly reducing the burden of subsequent verification. In the initial screening, the threshold can be appropriately relaxed to give priority to controlling false negatives (to avoid missing the screen); in the re-screening stage, it is necessary to strictly control false positives through repeated settings, gradient verification and other methods, and finally lock in the real dominant mutants.
-
Logical closed loop: directed evolution to achieve iterative optimization
High-throughput screening is a core driving step in the directed evolution cycle, not the endpoint. After obtaining a positive clone, its genotype needs to be analyzed through sequencing and used as a template for the next round of evolution to construct a new mutation library and enter the cycle of "library construction-screening-verification" again. This iteration is repeated until the performance of the enzyme meets the final application requirements.
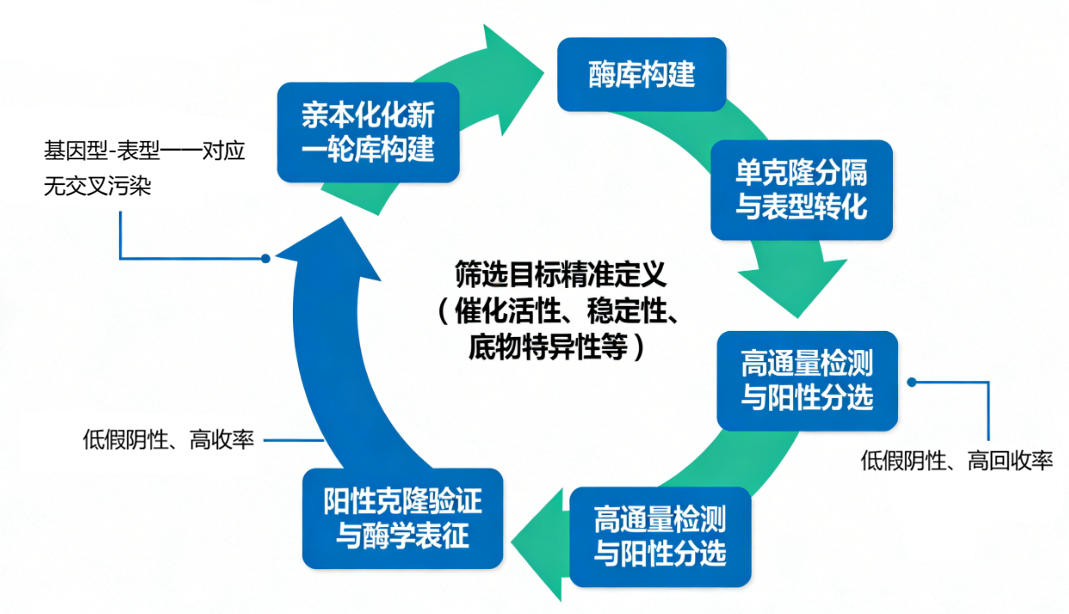
Figure 2 The underlying logic of high-throughput enzyme screening
3. Practical steps of the whole process of high-throughput enzyme screening
A complete set of high-throughput enzyme screening experiments can be divided into 6 core stages. Each stage has critical quality control points and is indispensable.
-
The development and verification of the screening system is the core prerequisite for high-throughput enzyme screening. It is necessary to first clarify the basic parameters of the target enzymatic reaction and the quantitative method of the substrate product, develop a transformation system with enzyme activity that can detect optical signals, and finally ensure that the system stability reaches the standard through Z-factor verification and eliminate interference caused by matrices such as bacterial lysates.
Z-Factor This is the industry-recognized gold standard for stability in high-throughput screening systems:
The calculation formula is: Z factor=1-(3σpositive+3σnegative)/|μpositive-μnegative|
Z factor>0.5: Excellent screening system with extremely low false positive/false negative rate and can be stably used for high-throughput screening
0.3<Z factor<0.5: Available system, conditions need to be optimized to reduce fluctuations
Z factor <0.3: The system is unusable and cannot be used for high-throughput screening.
-
Enzyme library construction and quality identification require the selection of natural metagenomic libraries, directed evolution mutant libraries, or AI-designed mutation libraries based on the screening goals. At the same time, library capacity, clone positivity rate, and mutation site diversity must be strictly controlled to ensure that library capacity and diversity meet screening needs.
-
To build a single clone isolation and coupling system, it is necessary to select a screening platform corresponding to microwell plates, microfluidic droplets or flow cytometry based on the expected screening throughput to achieve physical isolation of a single reaction unit corresponding to a single genotype, ensure accurate coupling of genotype and phenotype, and eliminate cross-contamination.
-
High-throughput preliminary screening and positive enrichment require the induction expression and catalytic incubation of the enzyme under strict control of the reaction in the linear range. The reaction signal is read through high-throughput by corresponding equipment, and the sorting and enrichment of positive clones is completed with reference to the set threshold of the control sample. In the preliminary screening stage, false negatives are given priority to avoid missed screening.
-
Rescreening and system verification of positive clones requires first eliminating false positive clones through single colony purification and multiple well rescreening, then completing comprehensive enzymatic characterization of the remaining positive clones, and finally obtaining the complete coding gene sequence corresponding to the target enzyme through sequencing.
-
The iterative optimization closed loop requires the construction of a new round of mutant libraries using qualified positive clones as parents, repeating the complete screening process until the enzyme's various properties meet the requirements for industrial application, and completing the corresponding pilot and scenario application verification.
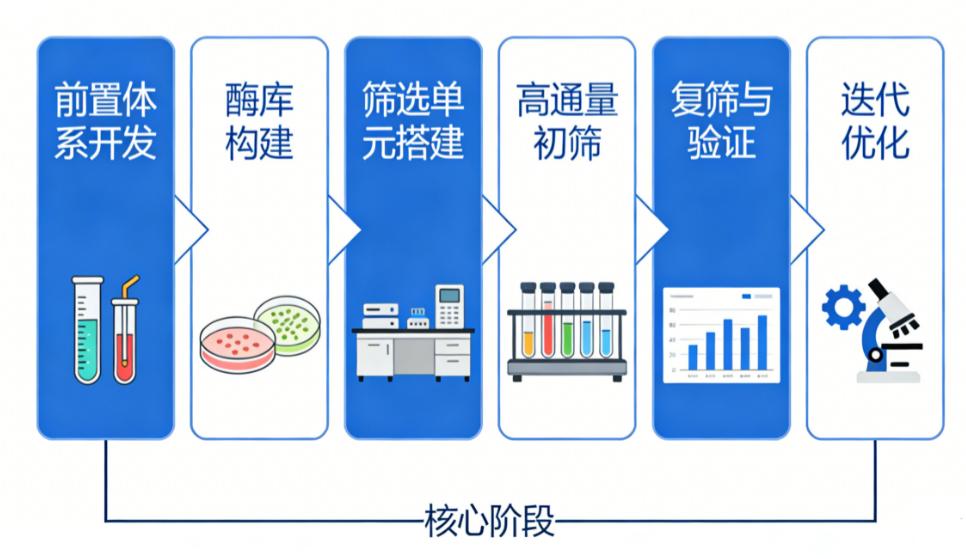
Figure 3 Practical flow chart of high-throughput enzyme screening
4. Industrial Applications and Future Prospects
High-throughput enzyme screening technology is the core infrastructure for the industrialization of synthetic biology. Its applications have fully covered the fields of industrial biocatalysis, biomedicine, agriculture and environment, providing efficient support for the development of key enzymes in pharmaceutical intermediates, bulk chemicals, bio-based materials, antibody drug conjugation, mRNA vaccines, diagnostic reagents, pesticide degradation, environmental remediation and biomass conversion.
At the same time, AI-assisted enzyme design and high-throughput screening have formed a tight closed loop of "AI design-experimental screening-data feedback", significantly shortening the enzyme engineering development cycle. In the future, with the deep integration of microfluidics, single-molecule detection and AI technology, this technology will develop in the direction of higher throughput, lower cost, more precision, and closer to real industrial scenarios, completely breaking the bottleneck of traditional enzyme engineering development and comprehensively promoting the upgrading and explosion of the biomanufacturing industry.