高通量酶筛选:如何从亿万候选者中,找到你的“天选之酶”?
在合成生物学与生物催化产业爆发的今天,酶作为 “生物催化的核心芯片”,其催化效率、底物特异性、稳定性等性能,直接决定了生物制造工艺的成本上限与工业化可行性。
传统摇瓶或单管筛选方法,单日通量不过几十到几百个克隆,早已成为酶工程应用的瓶颈。面对天然宏基因组库、定向进化库或AI设计库中动辄上万、百万乃至上亿规模的基因型多样性,传统方法已明显力不从心。
而高通量酶筛选技术的出现,将酶活筛选通量提升了成千上万倍,将原本需要数年完成的酶定向进化周期,大幅压缩到数月甚至数周之内,成为突破这一瓶颈的关键利器。
今天,我们就来深入聊聊高通量酶筛选的核心逻辑与实战流程。
一、高通量酶筛选的核心原理
高通量酶筛选的本质,是将酶的催化活性(表型),精准转化为可被高通量设备快速检测、量化、分选的物理信号,同时保证酶的编码基因(基因型)与对应表型的绝对一一对应,最终从海量酶库中快速富集获得符合目标性能的酶分子。它核心原理可拆解为两部分:
-
酶活信号的可检测化、高信噪比转化
酶的催化反应本身无法被设备直接读取,必须通过一套稳定的体系,将 “底物转化为产物” 的催化过程,转化为可量化的光学信号(主流为吸光度、荧光、化学发光),这是筛选的前提。
根据底物的转化方式,又可以将检测体系分为两类:直接检测体系和间接偶联检测体系。
直接检测体系:这类方法的原理是利用底物或产物自身携带可被检测的标记(如光学基团),催化反应能直接引起信号变化。例如,通过荧光共振能量转移(FRET)底物、发色团修饰底物等,反应前后的荧光强度或吸光度变化可直接反映产物生成量,从而与酶活性正相关。其优点是操作简便、背景干扰小、易于实现自动化,尤其适合用于超高通量筛选。
间接偶联检测体系:通过 1-2 步偶联酶反应,将目标催化反应的产物,转化为可检测的光学信号。最常见的如脱氢酶偶联体系,通过检测辅酶 NAD (P) H 在 340nm 处的吸光度或 460nm 处的荧光,间接量化目标反应的进程。优势是适配性广,绝大多数酶促反应都可通过偶联实现信号转化。
-
超高通量的单克隆分隔与信号分选
传统筛选的通量瓶颈,在于反应体积大、无法实现平行化的单克隆隔离。高通量筛选的核心突破,是通过微体积反应单元,实现单克隆的绝对物理隔离,每个反应单元仅包含 1 个基因型的酶及其催化反应体系,避免信号交叉污染,同时实现百万级的平行反应。
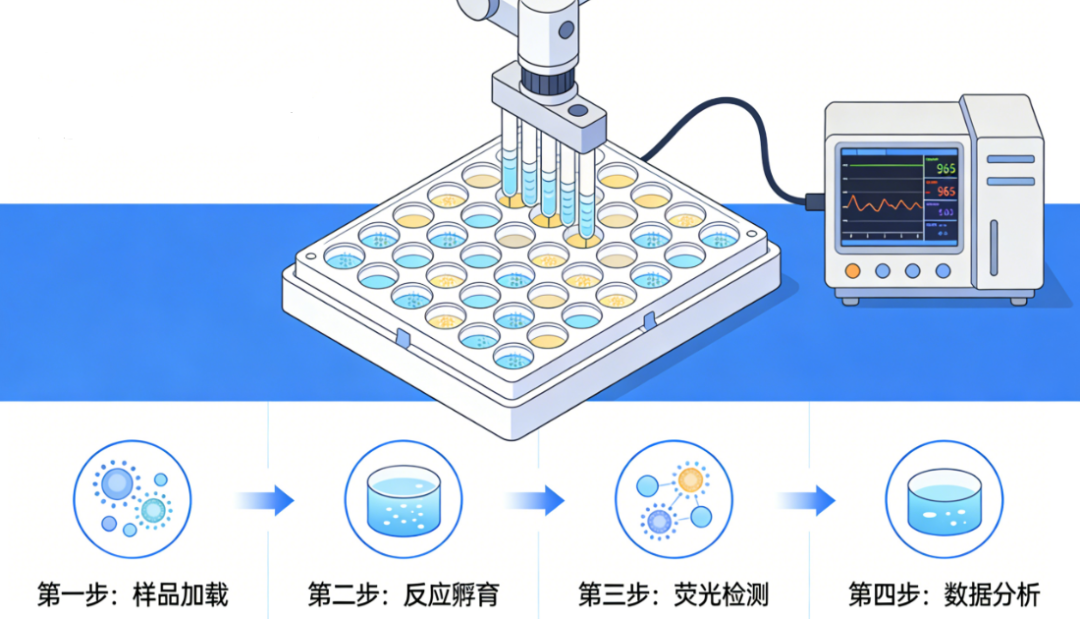
图1 高通量酶筛选的核心步骤
二、高通量酶筛选的底层逻辑
许多从业者在酶筛选中失败,根源往往不在于操作技术,而在于未能厘清筛选背后的根本逻辑。高通量酶筛选并非“一次性的检测实验”,而是一个从目标定义到验证迭代的完整工作闭环。其底层逻辑可拆解为四个核心环节,环环相扣,缺一不可。
-
逻辑起点:精准定义筛选目标
真正的筛选起点并非构建文库,而是明确“到底要筛出什么样的酶”。必须将模糊的应用需求,转化为可在实验中测量、并能施加选择压力的具体指标,主要包括:
(1)核心催化功能:目标底物、目标产物、反应类型。
(2)核心性能指标:如活性阈值、底物特异性、对温度/酸碱/有机溶剂的耐受性、催化转化率等。
(3)真实筛选压力:筛选体系应尽可能模拟实际工业应用环境(如高温、高底物浓度、存在有机溶剂等),否则筛出的酶很可能无法落地。
-
逻辑核心:确保基因型与表型的可靠关联
这是整个筛选体系的灵魂所在,也是多数失败案例的根源。所谓“基因型-表型关联”,是指检测到的“高活性信号”(表型)必须与编码该酶的基因(基因型)一一对应、严格绑定,避免信号混杂或基因信息丢失。一旦关联失效,即使检测到强阳性信号,也无法追溯到对应的基因,筛选即告失败。不同的筛选平台(如微孔板、液滴、表面展示)其关联机制各不相同,需针对性设计。
-
逻辑关键:高效特异地富集阳性克隆
高通量筛选的核心目标,并非“一次实验找到完美酶”,而是从海量文库中高效、特异地富集有潜力的阳性克隆,大幅降低后续验证的负担。在初筛时,可适当放宽阈值,优先控制假阴性(避免漏筛);在复筛阶段,则需通过设置重复、梯度验证等方法,严格控制假阳性,最终锁定真正的优势突变体。
-
逻辑闭环:实现迭代优化的定向进化
高通量筛选是定向进化循环中的核心驱动步骤,而非终点。获得阳性克隆后,需通过测序解析其基因型,并以此作为下一轮进化的模板,构建新的突变文库,再次进入“建库‑筛选‑验证”的循环。如此反复迭代,直至酶的性能满足最终应用要求。
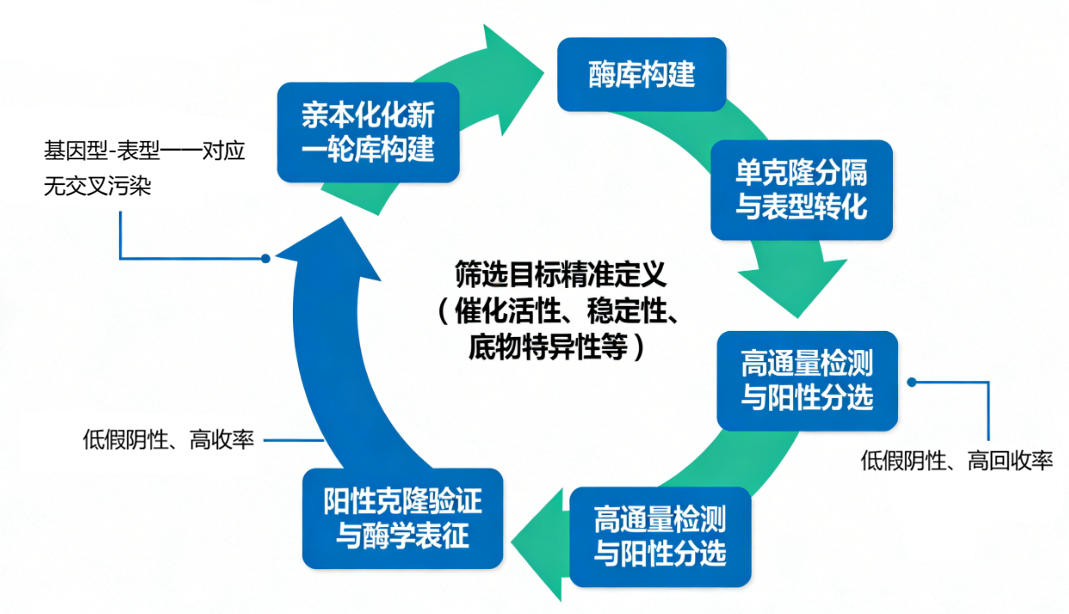
图2 高通量酶筛选的底层逻辑
三、高通量酶筛选全流程实操步骤
一套完整的高通量酶筛选实验,可分为 6 个核心阶段,每个阶段都有关键质控点,缺一不可。
-
筛选体系开发与验证是高通量酶筛选的核心前提,需先明确目标酶促反应的基础参数与底物产物定量方法,开发酶活到可检测光学信号的转化体系,最终通过 Z 因子验证确保体系稳定性达标,排除菌体裂解液等基质带来的干扰。
Z 因子这是业内公认的高通量筛选体系稳定性金标准:
计算公式为:Z因子=1-(3σ阳性+3σ阴性)/|μ阳性-μ阴性|
Z 因子>0.5:优秀的筛选体系,假阳性 / 假阴性率极低,可稳定用于高通量筛选
0.3<Z 因子<0.5:可用体系,需优化条件降低波动
Z 因子<0.3:体系不可用,无法用于高通量筛选
-
酶库构建与质量鉴定需根据筛选目标选择天然宏基因组库、定向进化突变体库或 AI 设计突变库完成构建,同时严格把控库容、克隆阳性率与突变位点多样性,确保库容量与多样性满足筛选需求。
-
单克隆隔离与偶联体系搭建需根据预期筛选通量选择微孔板、微流控液滴或流式细胞术对应的筛选平台,实现单反应单元对应单基因型的物理隔离,保证基因型与表型的精准偶联,杜绝交叉污染。
-
高通量初筛与阳性富集需在严格控制反应处于线性区间的条件下完成酶的诱导表达与催化孵育,通过对应设备高通量读取反应信号,参照对照样本设定阈值完成阳性克隆的分选富集,初筛阶段优先控制假阴性避免漏筛。
-
阳性克隆的复筛与系统验证需先通过单菌落纯化与多重复孔复筛剔除假阳性克隆,再对留存的阳性克隆完成全面的酶学性质表征,最终通过测序获得目标酶对应的完整编码基因序列。
-
迭代优化闭环需以验证合格的阳性克隆为亲本构建新一轮的突变体库,重复完整的筛选流程,直至酶的各项性能满足工业化应用要求,完成对应的中试与场景化应用验证。
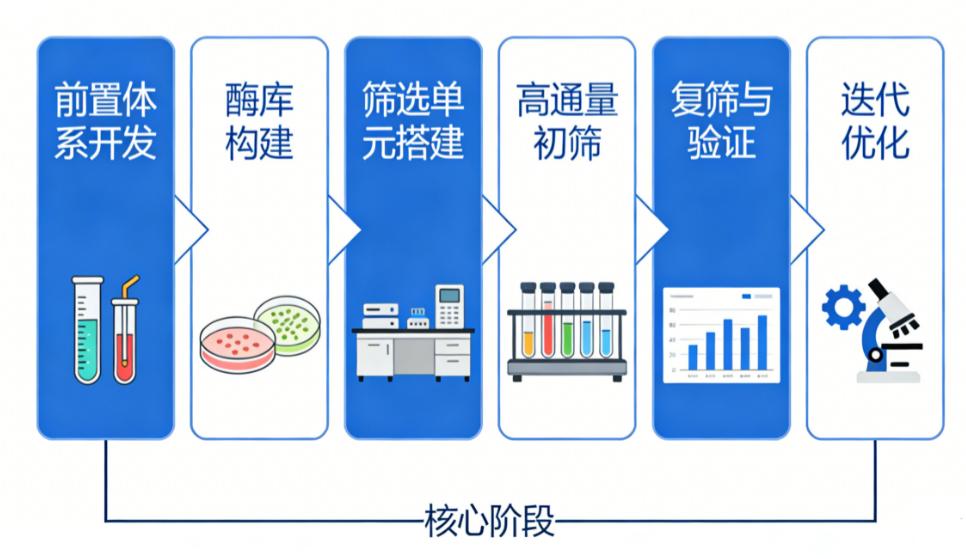
图3 高通量酶筛选实操流程图
四、产业应用与未来展望
高通量酶筛选技术作为合成生物学产业化落地的核心基础设施,其应用已全面覆盖工业生物催化、生物医药、农业与环境等领域,为医药中间体、大宗化学品、生物基材料、抗体药物偶联、mRNA疫苗、诊断试剂、农药降解、环境修复与生物质转化等方向的关键酶开发提供高效支持。
同时,AI辅助酶设计与高通量筛选已形成“AI设计-实验筛选-数据反馈”的紧密闭环,大幅缩短酶工程开发周期。未来,随着微流控、单分子检测与AI技术的深度融合,该技术将朝着更高通量、更低成本、更精准、更贴近工业真实场景的方向发展,彻底打破传统酶工程开发瓶颈,全面推动生物制造产业升级与爆发。